“This is how the economy comes to know itself.”
Gregory Norris, Director of Sylvatica
Companies are increasingly being pressured to “be green,” although it is not always clear what this means. Upon closer examination, the concept of green can be seen as an emergent quality of the interactions between many companies, many chemicals, and our environment, all driven by our collective purchases. This tangled web can be better understood with the right analysis methods, software, and data, but these resources are currently scarce and expensive. Companies needing to navigate this landscape can invest their intellectual capital by encouraging the construction of an open environmental infrastructure of tools and data. This article discusses the analysis methods, software, and data that can be used to help companies, the economy, and society become greener, faster.
Understanding Green
“What we want,” Jim said, “is to know if we can switch suppliers without encouraging more pollution.” He was concerned how his purchasing decisions would be viewed by his customers and environmental groups. Jim uses millions of glass bottles each year, and he is very careful to maintain his brand image as a responsible company. He continued to explain his dilemma.
“We currently buy from a glass facility right here in the United States. And now we’re looking at a plant in Asia, but there are a lot of reservations about the additional miles the bottles will travel to get here. We know that the Asian facility is new, and the American one is not. So our question is, ‘Do the energy efficiencies of glass from this Asian plant outweigh the environmental burden of shipping them half-way around the world?' ”
Jim’s concerns are not unique. He wants to buy green, but there is no clear definition of what green might be. In this case, a basic heuristic that people employ to understand whether something is green has failed. One often thinks of local goods as better for the environment because of reduced shipping needs. However, Jim found himself in a position where he questioned this proposition, and went looking for a quantitative answer.
As it turned out, Jim’s instinct was correct. When all the data were gathered and analyzed, it was clear that the most environmentally impactful part of the glass bottle supply chain is actually fabricating the product. Meanwhile, the burden from final shipping to the United States was minimal. These facts, combined with the energy efficiency of the Asian facility meant that, despite its long journey, the foreign glass was much ‘cleaner’ than the domestic option.
Life-Cycle Research
In the above anecdote, something important was glossed over: how was the glass bottle data gathered, and how was it analyzed? The comparison of the two glass bottle suppliers was made across the entire supply chain, which includes raw material extraction, transportation to the glass factory, glass making, packaging, and final delivery. Industrial activities used in each of these steps were included, such as making the cardboard box for packaging, and growing the trees to make the cardboard box. One could continue to describe how the delivery trucks were made, or the construction of the glass facility, but the point is that these studies aim to be very comprehensive. The studies are often called Life Cycle Assessments (LCAs). LCA is a standardized practice described by the ISO series 14040 standard.
The building block of an LCA is a unit process which represents one node in a supply chain. Once a unit process’ data are specified, it can be connected to other nodes in a series of sales and purchases. An economic network emerges that represents how goods and services are exchanged in the real world. To gather data for a unit process, one answers the following four questions:
-
What do you sell?
-
What do you buy?
-
What do you emit to air, water, land?
-
What do you extract directly from nature?
Figure 1: The LCA Unit Process
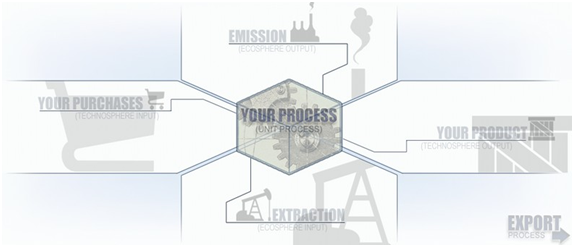
The LCA for glass making might go something like this:
-
What do you sell? One 120cc glass bottle.
-
To make your product, what do you buy? 100 grams of sand, 10 grams of soda powder, 7 grams of limestone, 3 grams of dolomite, 0.5 grams of inorganic chemicals, 0.5 kWh of electricity, 0.05 MJ of heavy fuel oil, and 100 grams of waste disposal services.
-
To make your product, what do you emit? 6.2 grams of carbon dioxide to air, 0.5 grams of nitrogen oxides to air, 0.03 grams of sulfur dioxide to air, 0.003 grams of hydrogen chloride to air, 0.05 grams of total suspended solids to water, and 0.0001 grams of zinc to water.
-
To make your product, what do you extract? 1.4 cubic metres of water from the river.
Of course, for this glass-making process to connect to its sand purchase, there must be a unit process for sand. There must also be unit processes for limestone, dolomite, electricity, and all the other purchases. Jim will want to connect his unit process to this glass making process as one of his many purchases.
The array of connections can quickly become dizzying as every activity in the economy needs a unit process. Where there are no company-specific unit processes, generic databases that give production recipes and emissions factors on average, such as for all coal-fired electricity plants in the US, are used. We are always looking to improve them with primary data directly from the companies.
This power to dig into one’s supply chain is very valuable, transformative, and sensitive. Supply chains go on indefinitely and are interwoven into a tightly interdependent network to form our economy. When Jim purchases a glass bottle, the glass factory purchases electricity, which uses glass somewhere in its supply chain, which uses electricity, which uses glass somewhere in its supply chain, and so on, to infinity. Other exchanges, such as coal and electricity, are more closely coupled, with each successive purchase smaller than the previous. This is an infinite series in mathematical terms.
It is worthwhile to reflect on what this all means. Is every company part of every other company’s supply chain? How many tiers back must we go to see this phenomenon happen? How do we assign responsibility for pollution in a world where it takes billions of parties, all pushing on each other, to make the pollution happen? Is it the seller’s fault? Is it the buyer’s fault? Is it the consumer’s fault? Is it even worthwhile to try to parse responsibility, or should we just accept that our neighbour's pollution is also ours? Just as it takes “two to tango,” it apparently takes “billions to pollute.” The infinite loops in our economy tell us that we are literally all in this together.
Important Challenges in the LCA World
One can look at an economy as a big network whose behaviour we are trying to understand and moderate. LCA attempts to break apart the economy into its fundamental building blocks and to examine how they interact to produce that high-level behaviour. The discipline considers unit processes to be those fundamental blocks. We have much work to improve LCA data, software, and methodologies. We will discuss important aspects of the first two. Good data and capable software with current LCA methodologies can dramatically change how business is done, and how we live by extension.
Data Collection
The information needed to build unit processes for each economic process is all around us. Companies know what they buy and what they sell. Larger companies with facilities that contribute the most pollution to the atmosphere, surface waters, and landfills generally know the details of what they emit. What is rarer is that these data are assembled together in a way that specifies purchases, emissions, and extractions per unit of product or service produced. All the pieces to create unit processes often exist in organizations, but they are not yet co-ordinated across departments to create a product-oriented view.
One major challenge for LCA is to gather these data and make them available to downstream supply-chain actors. While this is not a difficult process in theory, it takes quite a bit of effort because information systems and company departments are not set up to analyze process operations this way. Collection of the environmental data invariably falls into the lap of operations or environmental engineers, who have other priorities, and are not accustomed to dealing with customer requests. The real difficulties often lie in the gathering of purchasing information where the main barrier is confidentiality. Companies do not want to disclose what they are buying to fill their product orders. It’s a very sensitive topic. Overall, today’s LCA data collection is onerous, expensive, time-consuming, and difficult to navigate because the data are controlled by different people, with varying levels of trust for outside LCA researchers and consultants.
Data Sharing & Tools
The calculation of an LCA doesn’t require access to all the unit processes in a supply chain. A unit process can be aggregated into a system process. A system process blends the emissions from all purchases with a unit process’ direct emissions, and presents it as if it were the pollution of the unit process itself. In other words, a system process obscures the purchases in a supply chain, while maintaining the vital environmental emissions information. Companies may:
-
create a unit process
-
connect to their supplier’s system processes
-
aggregate their own unit-process into a system process
-
make their system process available to their customers
The cycle can continue throughout the entire supply chain, enabling all actors to have supplier-specific life-cycle information without direct disclosure of sensitive purchasing and process information. One very important consideration, which is inevitably the first objection raised, is how exactly are unit process data verified to ensure their accuracy and reliability? Some have envisioned a profession similar in nature to financial auditing, in combination with algorithmic checks that look for anomalies from year to year. Some have advocated for a scarlet letter system that identifies past cheaters. Certainly, this problem is not yet settled.
Imagine a software application that would enable this type of interaction. It would allow companies to create a unit process for their product, and to connect to real system process data of suppliers. The company would also specify their emissions and extractions per product unit. They could then prioritize the activities in their supply chain that are causing the most environmental impact. Is it the steel purchase, the glass purchase, or one’s own natural gas combustion? Once environmental priorities are set, various alternatives can be compared. When the company has completed their unit process, and it has been validated, they have the option to publish it, thereby making it available for customers to use in their calculations. The cycle continues with participation from each producer, until our entire economy is connected.
The vision of the Earthster project is to create an open source application that enables confidential LCA calculation and linkage. The project is still in early phases, but it is safe to say that an application of this nature will emerge in the near future. Such software must ensure good data quality, confidentiality, and scalability to operate in a world where billions of economic transactions happen every day. This software should not be just one application. It should be many, operating in an ecosystem that has been built to encourage low-cost of participation and innovation. The ecosystem must be open, and at least some of these applications should also be open.
The Need for Open Source LCA Tools and Data
LCA is a pragmatic discipline, grounded in the notion that its use by individual actors will simultaneously benefit self-interested producers and the public at large. Companies can employ it to find pollution and inefficiencies in their supply chains during supplier selection, or it can guide their product development efforts. Green supplier selection or product design is a boon to the public both in terms of reduced pollution and as a source of inspiration to product designers.
To date, the LCA data and software model has been to develop centralized datasets and encapsulated desktop applications. Open LCA, an open source java application accessible through Eclipse, is one notable project. Such efforts have enabled the LCA profession to blossom as software greatly simplifies the gargantuan task of maintaining millions of links between unit processes in the economy, and the datasets are a reliable set of average information on which good LCA studies can be conducted. The database initiatives painstakingly map out the unit processes of many agricultural, industrial, and service processes in the economy at significant cost. Great care is taken within the LCA database initiatives to guarantee data quality and consistency, which is no small feat.
There is room, and perhaps a great need, for another kind of data and software model in the LCA world. This is a crowd-sourcing approach where the economy maps itself. Companies can move from using generic data to company-specific information about the products they are actually buying. There would be no centralized intermediary to slow or alter the flow of this information, just as there is no centralized clearing-house for product pricing in our current economy.
The costs of gathering and validating the data are huge, but this challenge can be tackled with widespread collaboration. A framework is needed to coordinate these efforts while also encouraging experimentation. The business case for such a framework is not clear, but our society’s need for it is. One can only hope we are able to build a common vision before fragmentation and lock-in from private vendors takes place. Proprietary applications will certainly contribute greatly to increased environmental transparency in supply chains, but it is important that at least certain pieces of this framework remain open source.
It is certain that the world needs an open source, flexible data exchange standard for LCA data. This task is complicated by virtue of LCA data never standing on its own, but rather always being part of a larger network. When a process leaves a software installation and is imported into another one, the receiving software must determine exactly where the process can be plugged into the existing network. This is a complex task and best practices are constantly evolving. An open and flexible data format should enable software applications the leeway to experiment with new ideas, without breaking the validity of the format or the ability to exchange basic information with other applications. There are currently two major LCA data formats, EcoSpold and ELCD. EcoSpold is controlled by the Swiss Non-Profit, EcoInvent, and ELCD is the data format of the European Life Cycle Data System. While these formats may not be technically open source, they may be able to serve many of the needs listed above. It remains to be seen if they can offer the necessary flexibility.
It is also important that there is at least one open source LCA-browser. This browser is software that enables a user to access the datasets, explore how processes are connected to each other, and identify major environmental hotspots in the supply chain. It allows users to create their own unit processes and publish them to the LCA network. The primary argument for at least one open source browser is to provide a basic platform on which individuals or small teams can innovate. The browser analogy can be continued by calling these small innovations add-ons or plug-ins. LCA is a quickly evolving field, and an open source core would encourage small-scale experimentation and learning. Major breakthroughs could then be integrated into the core open source browser.
As with the software, it is beneficial to have some open source datasets. High quality generic LCA data will always be required to fill gaps where companies are not reporting, and this is especially true for the next 10-20 years when those gaps will be significant. Collaboration on open source datasets can be a key component to improve generic LCA datasets. Transparent and open datasets may enable faster quality improvement because of their transparency. Industries and companies that perform poorly in these datasets are able to understand why and then fix the dataset, fix their production processes, or both. Transparency enables non-profits and research institutions to spot weak assumptions and offer better information.
One of the largest barriers to wide-spread implementation of LCA has been its high costs. It is expensive to collect the data and to design analysis tools. These costs are not operating costs, but rather startup costs. Once the data are collected, they can be re-used by everyone in the world at a small marginal cost. In this sense, the LCA community faces the same situation as many software makers and the music industry. However, the world needs LCA to become ubiquitous to address our current environmental imperative. As we build the LCA infrastructure, it can be extended to other aspects. Once we have detailed LCA models, we can go beyond environmental pollution and ask human rights questions of supply chains.
It is necessary to lower the costs of LCA for smaller enterprises and to show its value to larger corporations. This is achievable, provided we put the infrastructure in place, so that the world achieves maximum benefit. All interested parties must collectively work to foster an open ecosystem that promotes participation, innovation and the transformation of our economy by making it self-aware.
Summary
There is an increasing need for tools and data to address the environmental imperative. LCA is seen as an important contributor to this space due to its ability to cope with realistic interconnections of economic actors and to identify leverage points for environmental improvement. Collaboration is needed, and is emerging, to enable real-time, decentralized sharing of product environmental information. We must foster trust, participation, and experimentation to green our economy as quickly as possible, so our economic lives can reflect our values as a people.
The title of this article is derived from a quotation fragment by Pascal Lesage, Director of Sylvatica in Montréal.