"... the act of properly designing a complex system characterized by a modular architecture is not a trivial task. On the contrary, modularity bears high costs: careful modularization is a cognitive challenging activity, since it translates in devising a decomposition of the whole system in autonomous subparts whose interdependencies are reduced to the minimum. Moreover, failure to perfectly modularize an architecture results in costs of dealing with fine tuning and tempering activities aimed at solving unexpected and unforeseen interdependencies."
Modularity in Action: GNU/Linux and Free/Open Source Software Development Model Unleashed
Modularity of an open source software (OSS) code base has been associated with growth of the software development community, the incentives for voluntary code contribution, and a reduction in the number of users who take code without contributing back to the community. As a theoretical construct, modularity links OSS to other domains of research, including organization theory, the economics of industry structure, and new product development. However, measuring the modularity of an OSS design has proven difficult, especially for large and complex systems.
In this article, we describe some preliminary results of recent research at Carleton University that examines the evolving modularity of large-scale software systems. We describe a measurement method and a new modularity metric for comparing code bases of different size, introduce an open source toolkit that implements this method and metric, and provide an analysis of the evolution of the Apache Tomcat application server as an illustrative example of the insights gained from this approach. Although these results are preliminary, they open the door to further cross-discipline research that quantitatively links the concerns of business managers, entrepreneurs, policy-makers, and open source software developers.
Modularity and Design Structure Matrices
In Design Rules: The Power of Modularity, Baldwin and Clark present a major study of the role of modularity in the evolution of the computer industry. They argue that modularity is an important and fundamental connection between at least three different systems: i) the engineering design; ii) the organization of the people who implement and maintain the design; and iii) the network of companies forming the economic system around the design. Each system constrains and enables the other two. Other researchers have since built on and extended this work, which in its original form did not directly address OSS.
According to Baldwin and Clark, a module is a unit whose structural elements are strongly connected among each other and relatively weakly connected to elements in other units. Just as there are degrees of connectedness, there are degrees of modularity. This motivates the interest in metrics and techniques to measure the modularity of the structures comprising an artifact. In a widely-cited 2006 paper titled The Architecture of Participation: Does Code Architecture Mitigate Free Riding in the Open Source Development Model?, Baldwin and Clark provide a theoretical argument that a more modular open source code base will attract more voluntary contributions and have less free riding of non-contributors than one that is less modular.
When the complexity of one of the elements crosses a certain threshold, that complexity can be isolated by defining a separate abstraction that has a simple interface. This abstraction hides the complexity of the element and the interface indicates how the element interacts with the larger system. Modularity decreases complexity in several ways. In particular, it allows designers to focus on individual modules rather than the whole integrated artifact. This radically changes the design process and allows for work on individual modules to be parallelized.
The Design Structure Matrix (DSM) is an analysis tool for mapping complex systems. It provides a compact representation of a complex system that visualizes the interdependencies between system elements. According to Baldwin and Clark, "it is a powerful analytic device, because by using it we can see with clarity how the physical and logical structure of an artifact gets transmitted to its design process, and from there to the organization of individuals who will carry the process forward."
A DSM is a square matrix with off-diagonal cells indicating dependencies between the system elements. A value in the cell at row i and column j means that the element at position i depends in some way on the element at position j. For example, the design elements could be Java classes and dependencies would be references between classes. This information can be extracted automatically from the code base. Clustering reorganizes the DSM elements to more clearly visualize and analyze dependency relationships.
The details of how this analysis is conducted are quite technical, and it builds on prior research in several related domains. Alan MacCormack, John Rusnak, and other colleagues at Harvard Business School recently published two important advances. In a 2006 article titled Exploring the Structure of Complex Software Designs: An Empirical Study of Open Source and Proprietary Code, they employed DSMs to empirically compare the design structures of two software products: the Linux kernel and the Mozilla web browser. They proposed a clustering algorithm to measure dependencies. However, their comparison critically depended on selecting versions of the systems with a similar number of source files which were the elements in the DSM. One motivation of our work was to remove this restriction, and to allow the comparison of code bases of different size.
A follow-on article in 2008 examines the evolution over time of two software products: the open source Apache Tomcat application server and an unnamed closed source commercial server product. A coarse metric is introduced that represents the change ratio between the consecutive versions in the product evolution. The authors conclude that DSMs and design rule theory can explain how real-world modularization activities allow for different rates of evolution to occur in different modules, and create strategic advantage for a firm.
Measuring Design Evolution
Our method for examining the evolving modularity of large-scale software systems implemented in Java builds on the discussed DSM methods and algorithms, but differs from past work in several aspects. As with these approaches, we: i) automate dependency extraction from the software code base; ii) employ design structure matrices for visualization and analysis of dependency information; and iii) compute cost metrics as measures of modularity. We differ from the earlier work in: i) that our unit of analysis uses Java classes rather than C source files; and ii) our use of the relative clustered cost metric.
Our design elements are Java classes and our dependencies are references between classes, whether by inheritance, declared fields, or method calls. Because dependencies between Java classes can be extracted from the compiled code of a software system, we need only obtain binary distributions of the selected versions. The steps of our method are as follows:
- Select the versions to be analyzed and obtain their binary distributions.
- For each version, extract the depend- ency information from the compiled code.
- Create DSM instances and extract cost metrics.
We implemented three modularity metrics:
- Propagation cost: measures the extent to which a change in one element impacts other elements. It is a representation of the degree of coupling without consideration of the proximity between elements.
- Clustered cost: a more sophisticated metric that assigns different costs to dependencies based on the locations of elements within clusters. It has an important limitation in that it can only be used to compare DSMs of similar sizes.
- Relative clustered cost: (our contribution) extends the clustered cost metric to compare DSMs of different sizes, avoiding the limitation of the clustered cost metric.
More formal definitions of these metrics and details of their implementations will be seen in our upcoming presentation Design Evolution of an Open Source Project Using an Improved Modularity Metric.
Evolving Modularity of Tomcat
We used our method to study the evolving code base of an open source system, the Apache Tomcat application server developed and maintained by the Apache Software Foundation. Tomcat is implemented in Java, and has two major distinct functional modules: the Tomcat-main server core and Jasper, a separate module that processes Java Server Pages. Tomcat-main and Jasper are linked only through the J2EE API.
Over the ten-year period between 1999 and 2008, four major versions of Apache Tomcat were released:
- Apache Tomcat 3.x is based on the original implementations of the Servlet 2.2 and JSP 1.1 specifications donated by Sun Microsystems
- Apache Tomcat 4.x implements the Servlet 2.3 and JSP 1.2 specifications and Catalina, a new servlet container based on a different architecture
- Apache Tomcat 5.x implements the Servlet 2.4 and JSP 2.0 specifications
- Apache Tomcat 6.x implements the Servlet 2.5 and JSP 2.1 specifications
Since support for specific standards specifications is of primary importance to Tomcat users, major version numbers for Tomcat mirror the versions of the Servlet and JSP specifications that Tomcat supports. However, a change in major version numbers does not necessarily correspond to major changes in the structure of the code base. Thus, when we selected the versions of Tomcat for our analysis, we identified significant architectural events in the evolution of the Tomcat code base, such as major changes to the architecture to improve performance, or the introduction of the Catalina servlet container.
For each version, we examined the Tomcat-main and Jasper modules both separately and in combination. For each analysis, we computed the number of classes, number of dependencies, propagation cost, number of vertical busses, number of clusters, clustered cost, and relative clustered cost. The number of classes nearly tripled between version 3.0 and 6.0.16. This is clear evidence of the need for modularity measures that permit comparisons of code bases of different size.
Initially, we expected the modularity of Tomcat to increase throughout the evolution of the product. The rationale for this expectation was that as a system evolves, its structure would be continually examined by developers. Specifically, we expected that architectural improvements would also lead to increased modularity. For example, when Tomcat 4.x introduced a new implementation of the servlet container based on a new architecture (Catalina), we expected the new architecture to be more modular because it was built from the ground up for flexibility and performance.
However, as seen in Figures 1 and 2, we observe that the propagation costs for Tomcat 3.3.2 and 4.0.6 are 9.6% and 14.6%, respectively, and the relative clustered costs are 0.0031 and 0.0035. Both metrics suggest that version 4.0.6 is less modular than version 3.3.2, the opposite of what we expected to find. Version 3.3.2 is the latest production release of Tomcat 3.x which finished the refactoring effort and introduced a more modular design by allowing the addition and removal of modules that control the execution of servlet requests. Version 4.0.6 is the final release of Tomcat 4.x that introduced the Catalina servlet container. A similar pattern occurred when major architectural changes were made to the Jasper subsystem at other points in time.
Figure 1: Propagation Cost of Tomcat-main
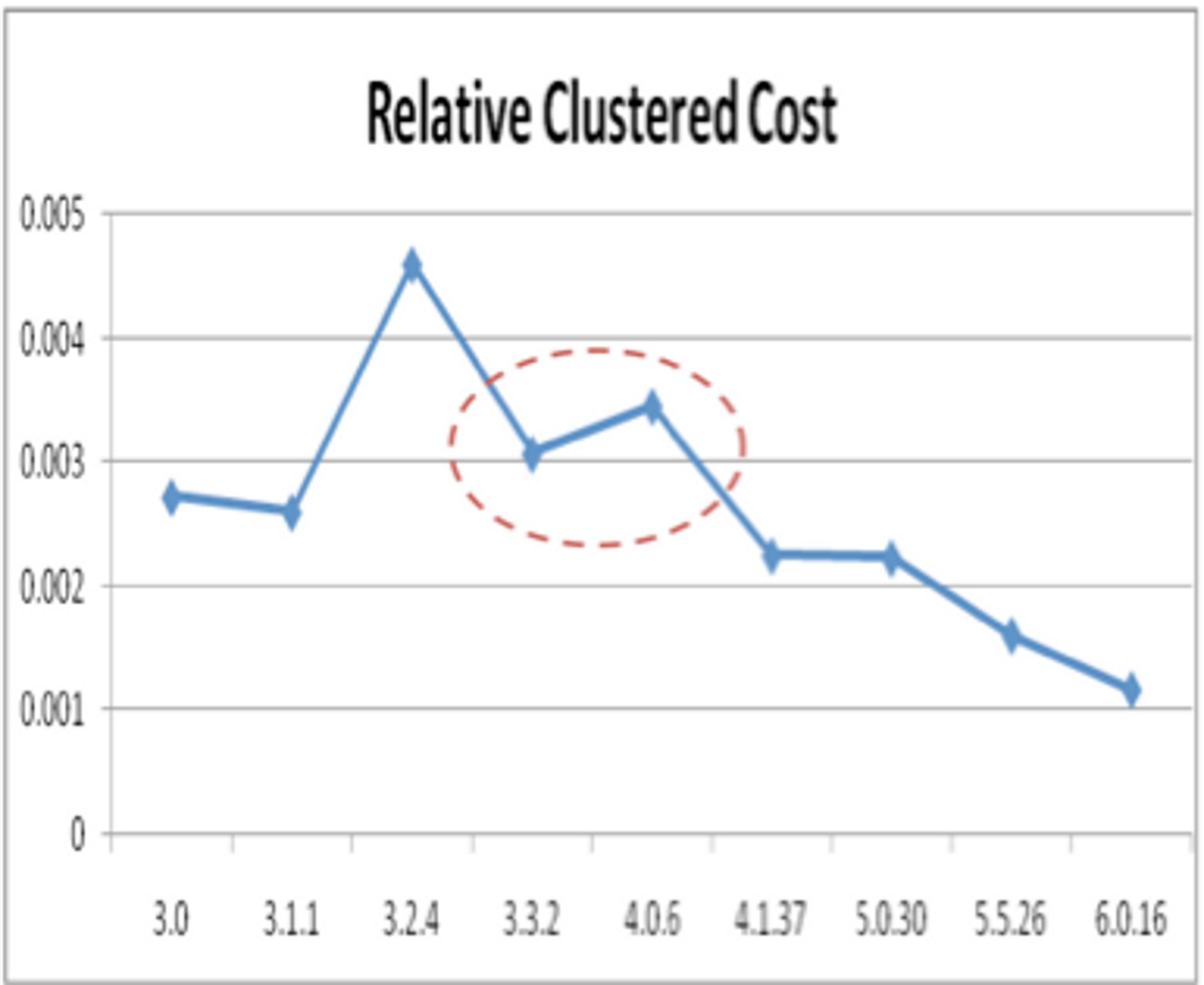
Figure 2: Relative Clustered Cost of Tomcat-main
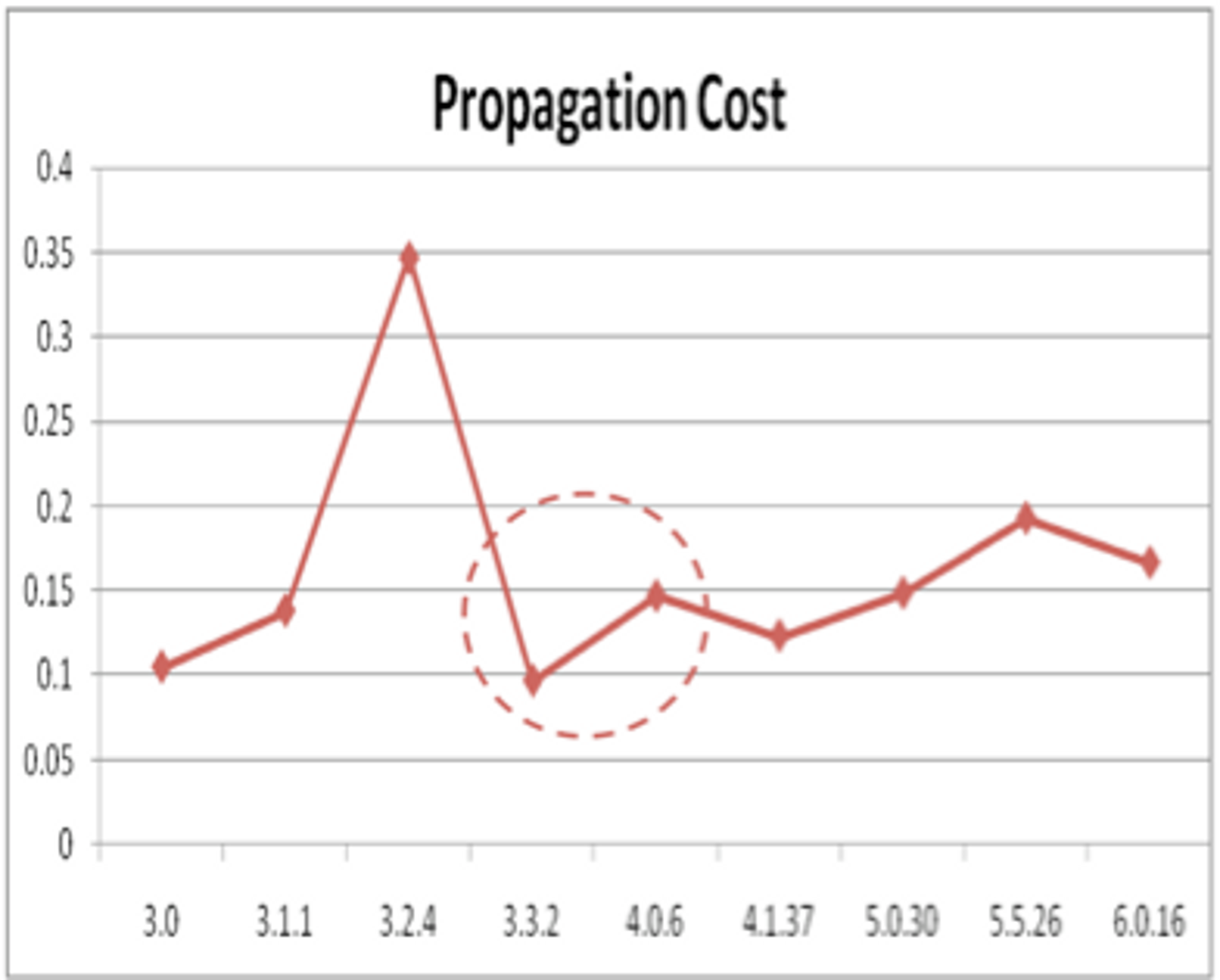
A closer examination of the events surrounding these spikes in propagation cost and relative clustered cost suggests that each decrease in modularity was precipitated by a major architectural or implementation change. For all other releases, whether major versions or incremental releases, the code became increasingly more modular. Interestingly, each spike is immediately followed by an increase in modularity. In fact, in each case, the increase in modularity of the consecutive version more than compensated for the previous decrease.
Our data is not conclusive on why this pattern occurred, but we offer a plausible explanation. Once new functionality is initially deployed and working, focus shifts. Developers revisit the design and perform refactoring and cleanup activities which represent changes to the structure of the system, but not to its behaviour. Increased understanding and experience gained through the original implementation permits developers to more easily restructure the existing code into a more modular design. The result is a significant increase in modularity that compensates for the original decrease in the previous version.
To capture these observations, we propose three propositions that can guide future research on the evolution of modularity of software systems:
Proposition 1: major architectural and implementation changes cause the modularity of a software system to decrease at first.
Proposition 2: major changes are followed by periods of refactoring and cleanup activities, which cause the modularity of the software system to increase again.
Proposition 3: the increase in modularity as a result of refactoring and cleanup activities more than offsets the decrease in modularity due to a major change.
Conclusion
This paper reported on recent advances towards understanding the evolution of large OSS systems, and proposed an improved modularity metric based on DSMs that allows the comparison of code bases of different size. Our research provides initial evidence that as a large software system evolves, major architectural changes, at first, lead to an increase in modularity, but are followed by refactorings and cleanup activities which lead to a subsequent increase in modularity.
Although these results are preliminary, they are part of the larger research program in which we hope to provide deeper insights into the connections between technical, organizational, and economic systems.
Recommended Resources