"A key advantage of the advent of open APIs is that many people can simultaneously tackle a particular problem by working on their own version of a mashup." Palfrey & Gasser
Mashups enable users to "mix and match" data and user interface elements from different online information sources to create new applications. The creation of mashups is supported by a complex ecosystem of interconnected data providers, mashup platforms, and users. In our recent research, we examined the structure of the mashup ecosystem and its growth over time. The main contribution of our research is a method for the analysis of mashup ecosystems. Its novelty lies in the development of techniques for mapping the mashup ecosystem, and the use of network analysis to obtain key characteristics of the ecosystem and identify significant ecosystem members and their relationships. In this paper, we summarize the key steps of our analysis method, describe the members of the mashup ecosystem, and discuss the managerial implications of our analysis.
Mapping the Mashup Ecosystem
There are many public sources that provide information about open APIs, mashups, and associated platforms. One source, ProgrammableWeb.com, lists APIs and mashups by date of introduction, and provides a profile of each. It also categorizes APIs and mashups through a provided taxonomy and through tags that users can associate with the entries. In addition, the site provides information on mashup tools. Since the contents of the site are user-contributed, not all APIs and mashups in existence are indexed. However, the ProgrammableWeb is probably the most widely recognized mashup directory, and its contents can be considered representative of the state of the mashup ecosystem. Thus, while our analysis is likely to underestimate the total size of the mashup ecosystem, it can be expected to accurately represent the relations between ecosystem members.
First, we extracted time-stamped information on when APIs were introduced and when mashups were created. Next, we captured the relationships between mashups and APIs in an affiliation network. Originally developed for representing teams and their membership by Uzzi et al., the links in the affiliation network for the mashup ecosystem indicate which APIs are used in which mashups. Affiliation networks lend themselves to a visual analysis of the network data and many relationships only become apparent by visualization. Visual observations then direct the further analysis as to what aspects of the network to study.
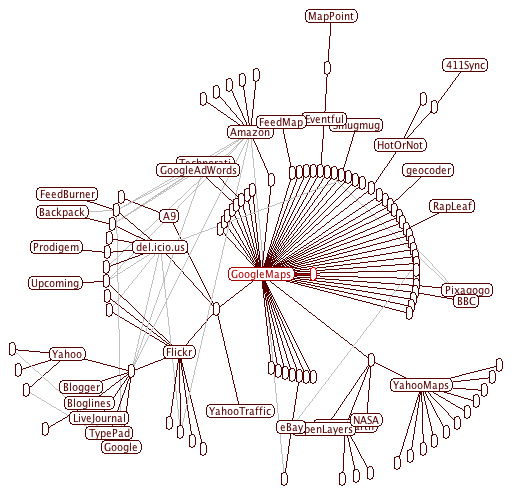
Figure 1 shows a snapshot of the mashup ecosystem using data based on the first month of records on the ProgrammableWeb site. Only the names of APIs are shown to keep the diagram readable, mashups are shown as unnamed nodes, and a link between a mashup and an API indicates that the mashup uses the API. Even at this early stage, some of the most well-known open APIs are already prominently positioned in the network. We find Google Maps at the center and other prominent APIs, such as Flickr, Amazon, Yahoo Maps and del.icio.us, along the first ring around the center. Named nodes at the periphery of the graph represent APIs that have been used less frequently. Similarly, there are many one-feature mashups, also known as widgets or badges, that combine only one external API with internal data.
Figure 1: Snapshot of Mashup Ecosystem
Members of the Mashup Ecosystem
Initially, there were two types of members within the mashup ecosystem: i) data providers that release open APIs, such as Flickr or Google; and ii) users and developers creating mashups. The only way for users to create mashups was by manually combining open APIs exposed by data providers. In some cases, data providers aggregate the data offered by other providers. For example, Google Maps obtains its raw map data from a number of geographic data services. Access to those data providers is often not directly accessible through open APIs, so an API such as Google Maps is not itself a mashup. Somewhat surprisingly, there are only a few mashups that offer their own APIs. We believe that the rationale for this is a combination of licensing issues and business reasons.
Open APIs and Mashups
Throughout the observation period, the data shows a consistent growth in the number of open APIs and mashups. Each day on average 0.70 new APIs were defined, from which users created an average of 3.10 mashups each day. On average, there are 4.41 mashups to each API. Such linear growth was also observed in other types of networks such as collaboration networks. However, the distribution of mashups over APIs is far from uniform, following a power law with a characteristic long tail. Some APIs enjoy significantly greater popularity than others.
One explanation for the long tail is competition between APIs that offer the same type of service. For example, multiple APIs provide map services such as Google Maps, Yahoo Maps and Microsoft's Virtual Earth. Choice requires user selection, and users will initially prefer some APIs over others. The more they select one API, the more likely it will be selected in the future. The result is that, eventually, one API will be significantly more popular than others. However, it also implies that a small number of APIs, the keystones of the ecosystem, provide the basis for the majority of mashups, and all other APIs are only used in certain application niches.
Complementary Nature of APIs
Open APIs are the components of mashups, and as such provide value to users by themselves. However, their value increases when other data providers offer complementary APIs that extend their functionality or allow them to be used in new contexts. For example, Flickr complements Google Maps, because it allows images about a given location to be shown on a map. In fact, the combination of these services was so compelling that both Flickr and Google decided to offer new services to show images on a map. APIs that have many complementary APIs are more attractive to users, and will be selected more often for inclusion in a new mashup.
Starting from the affiliation network that shows how APIs are used by mashups, we created a network that shows just the APIs, with links indicating which APIs are used together in a mashup. The network has a core that consists of a small number of highly connected APIs that are used by many mashups, and more specialized APIs that are linked to the core. The nodes in the core of the network are APIs which attract keystone data providers as well as niche data providers as complementors. In part, this is certainly due to an accumulation of coordination knowledge. As APIs are used together, users build up an experience base on how to integrate them, making those APIs more popular.
Mashup Platforms
As the number of APIs, and thus the complexity of selecting mashups and the value perceived by businesses of creating mashups increased, platform providers entered the ecosystem to fill the void. Initially, these were graphical tools, such as QEDWiki from IBM, to simplify the composition of APIs into mashups. Platform providers also quickly started to offer marketplaces for APIs and mashups. At present, there is no leading platform provider, nor a leading marketplace that could serve all user needs. We examined the increase in the complexity of mashups, measured as the average number of APIs combined in a mashup, and plotted it against the timing of the introduction of mashup platforms.
The first set of platforms included libraries, such as the Yahoo! User Interface Library (YUI), and templates such as those provided by the Ning social networking site. Later, the first hosted sites for mashups were introduced, such as Coghead. The first platform that can be considered a mashup composer, DataMashups.com, was also released around that time, as was the first platform, Dapper, for extracting implicit APIs from web sites. Almost two years after the publication of the first mashup, there was a flurry of releases of mashup composers, including the now defunct Teglo and QEDwiki as well as Yahoo! Pipes. Many of these composers also integrated interfaces to search for known APIs and to integrate them into a mashup.
We find that mashup platforms have increased in sophistication, from early hosting for mashups and screen scraping tools to more recent graphical mashup composers, in response to the increasing complexity of mashups and the needs of enterprise users. One of the major shifts has been in the types of mashups created: from one-feature mashups to mashups that combine multiple open APIs and internal data sources. The latter type of application requires more advanced tools.
Managerial Implications
The managerial implications encompass three areas related to the creation of mashups and the development of open APIs: i) selection of APIs; ii) introduction of new APIs; and iii) composition of APIs into mashups.
First, our research suggests that the position of a data provider in the mashup ecosystem affects the likelihood of their API being incorporated into a mashup. The number of mashups using a given API is a first indicator of how likely an API will be selected as the basis of a new mashup. For users, the popularity of an API is a signal of its quality. When users select an API, they will give preference to more widely used APIs. But popularity alone does not fully explain the how APIs are selected, except where a mashup consists of exactly one API. In all other cases, the number of interactions with other APIs also plays into the decision to select a given API.
The frequency with which APIs are combined in a mashup is an indicator of how likely they will be combined in future mashups. We observed that the positions of data providers in the mashup ecosystem are mutually reinforcing. One factor we would like to offer as an explanation is that when APIs are used together, significant experience on how to integrate these APIs is obtained. This, in turn, leads developers to prefer proven combinations of APIs when developing new mashups. Another likely factor is that mashups, as the literature on the role of imitation in innovation leads us to conclude, are developed by emulating existing mashups. In our research to date, we have not studied the impact of copying or cloning mashups on the mashup ecosystem.
This has implications for users of mashups and data providers. Users will select APIs based on how many other mashups use a given API, as well as the collective experience in using a given API with other APIs to be selected for the mashup. Data providers, when introducing a new API, will benefit from ensuring that their API integrates well with existing APIs that are strongly positioned in the mashup ecosystem. Data providers should look for opportunities to complement existing APIs. By complementing, the new API will also benefit the provider of the existing API by providing additional contexts of use and increasing its potential share of mashups that use it. In order to identify potential niches to enter, data providers need to gain a good understanding of the structure of the current ecosystem. Mapping the mashup ecosystem offers key insights for introducing your own API or mashup.
Second, our analysis suggests that the complexity of mashups drives the development of mashup platforms. The design of more complex mashups requires more sophisticated platforms. This coincides with the increasing interest in enterprise applications of mashups, which may itself be a major contributor to higher complexity. Platform providers need to introduce tools that help manage this complexity. Complexity introduces challenges in searching for APIs, enforcing design rules during the composition of APIs, and certification of APIs. The selection of APIs turns into a problem of finding the right combination of APIs for a given purpose. Enforcing design rules requires a codification of integration experience so it can, at least partially, be automated by a tool. Finally, APIs need to be certified in terms of meeting quality standards.
Conclusion
We have described an approach to map the structure of the mashup ecosystem and its growth over time. The approach uses visualization to show the relationships between APIs and mashups, and subsequently uses network analysis to obtain key characteristics of the ecosystem and identify significant ecosystem members and their relationships. We also discussed the managerial implications of our analysis for data providers, mashup developers, and developers of tools or platforms for the development of mashups. Future work includes answering the question what laws underlie the growth of the mashup ecosystem and the mechanisms of the creation of mashups. Due to availability of rich data about its structure and growth, the mashup ecosystem gives us a glimpse at innovation processes. We believe that results from the examination of the mashup ecosystem can also shed light on the nature of innovation and of ecosystems in general.